



Pareto Rule Application - Feature Reduction in Data Science
Feature reduction in data science practices can help cut data requirements significantly without increasing commercial risk while enhancing business insights.

In the realm of data science, the art of feature reduction exemplifies a fascinating parallel with one of the most enduring principles in business and economics - the Pareto Rule, also known as the 80/20 principle. Just as Vilfredo Pareto observed that roughly 80% of effects come from 20% of causes, data scientists often discover that a similar proportion of model performance can be achieved using only a subset of available features. This principle not only streamlines the modeling process but also enhances model interpretability and computational efficiency.
The synergy between feature reduction techniques and the Pareto principle offers valuable insights into how we can optimize machine learning models without sacrificing significant predictive power. By understanding and leveraging this relationship, data scientists can build more efficient and practical models while maintaining robust performance levels.
This demonstration shows how existing tools and technologies can make these capabilities more intuitive, without requiring complex programming—especially for business users. I will use KNIME and WEKA platforms to showcase this approach in the example below.
Dataset Description
This dataset is a synthetic version inspired by the original Credit Risk dataset on Kaggle and enriched with additional variables based on Financial Risk for Loan Approval data. This is currently available on Kaggle here.
Outcome
Our goal is to develop a classification model that helps banks determine whether to offer loans to customers based on specific attributes. The dataset contains 50,000 records with 14 attributes, which we'll use to predict loan approval status for prospective customers.
Solutions Approach
This exercise focused on analyzing the cleansed Kaggle dataset to determine whether we could achieve comparable model accuracy using fewer attributes.
Part 1- Utilizing WEKA for Feature Reduction
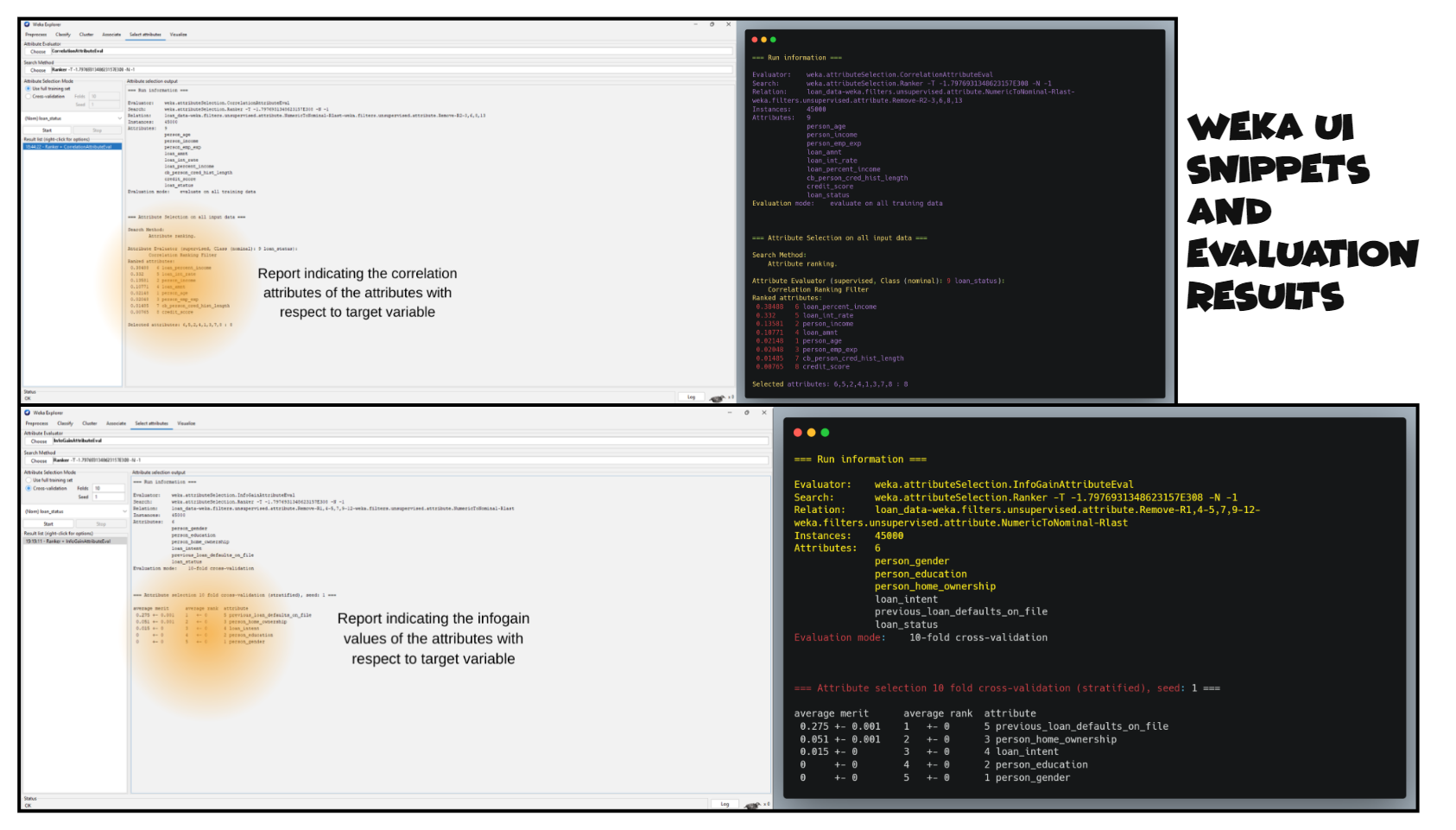
The WEKA Data Mining tool proved more effective than KNIME for feature reduction, offering straightforward no-code capabilities that were relatively easier to implement specifically for attribute selection. I used two main techniques to analyze both string-type and numeric-type attributes in relation to the target variable 'loan_status'.
Analysis using the InfoGain algorithm revealed that both 'person's education' and 'person's gender' attributes provide no significant information about loan approval status. For numeric attributes, we used correlation analysis to determine which variables most strongly correlate with the target variable.
Part 2 - Data Imbalance and Model Training
Although WEKA offers many useful features, KNIME's more user-friendly interface and capabilities provide greater flexibility. I primarily use WEKA only for tasks that are difficult to accomplish in KNIME.
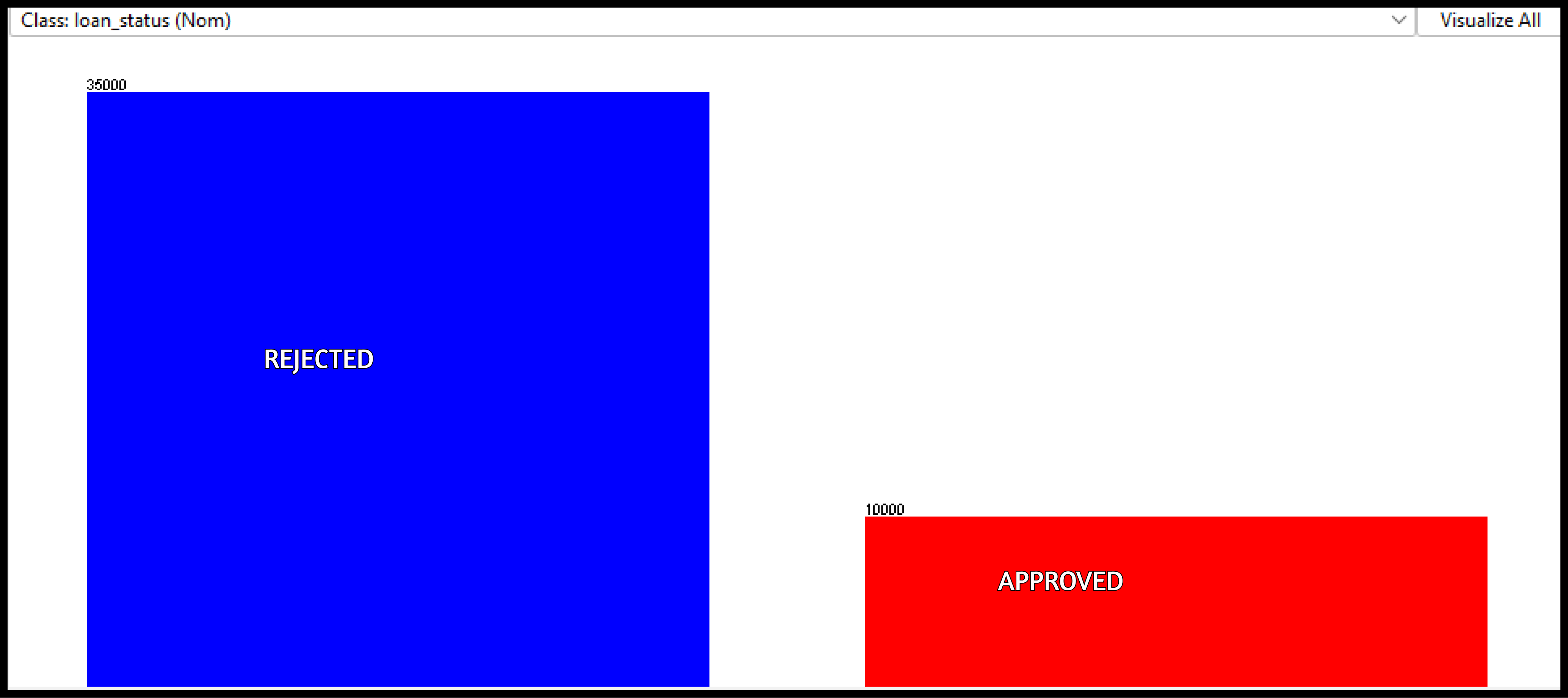
The complete dataset clearly shows much higher number of loan rejections compared to approvals. As a result, we would need to utilize Stratified sampling based on the ‘loan_status’ column as part of the Modelling exercise.
Part 3 - Feature Selection
Using the WEKA Data Mining tool, we evaluated parameters to create two data subsets:
One subset containing 11 features
Second subset containing 7 features
Due to the imbalanced nature of the data, we used Cohen's Kappa measure to evaluate model accuracy across the full dataset and both subsets.
The following scale is commonly used to interpret Cohen's Kappa values in machine learning model evaluation:
≤ 0: Poor agreement (no agreement or worse than chance)
0.01-0.20: Slight agreement
0.21-0.40: Fair agreement
0.41-0.60: Moderate agreement
0.61-0.80: Substantial agreement
0.81-1.00: Almost perfect agreement
For most ML applications, a Kappa value above 0.60 (substantial agreement) is considered good, while values above 0.80 are excellent. However, the acceptable threshold may vary depending on your specific application and domain requirements.
In our specific use case, the Cohen's Kappa values for all three datasets showed comparable performance, suggesting we can use a selected subset of attributes instead of the complete dataset for future predictions.

We should also consider additional perspectives when evaluating our reduced feature selection, particularly regarding business risks.
Given our unbalanced dataset with more rejections than approvals, it's crucial to assess the risk of false positives—where bad accounts are incorrectly identified as good ones. These misclassifications could lead to bad debts on the company's balance sheet in real-world applications.
To assess this risk, we'll examine the False Positive Rate metric and compare it across all three datasets for the "Approved" criteria. We selected this metric based on the guidance provided in the table below.

As visible in the below stated graphic, there is not a significant shift in the FPR metric but, the organization can consider bringing down their data requirement for evaluating loan approval requests by ~50% without incurring any additional risk.

Conclusion
While this example uses artificial data, real-world organizations often track and evaluate numerous attributes to predict customer behavior in sales processes. Implementing feature reduction techniques can help organizations optimize their operations.
This optimization delivers significant commercial value through:
Reduced data storage requirements
Reduced data compliance requirements and associated regulatory risks
Reduced data collection efforts
From a business perspective, this exercise helps validate existing logic and deepens our understanding of which features truly influence prediction outcomes. This improved business understanding becomes a valuable knowledge base for future deals and negotiations.
Quick Side Note (for KNIME enthusiasts)
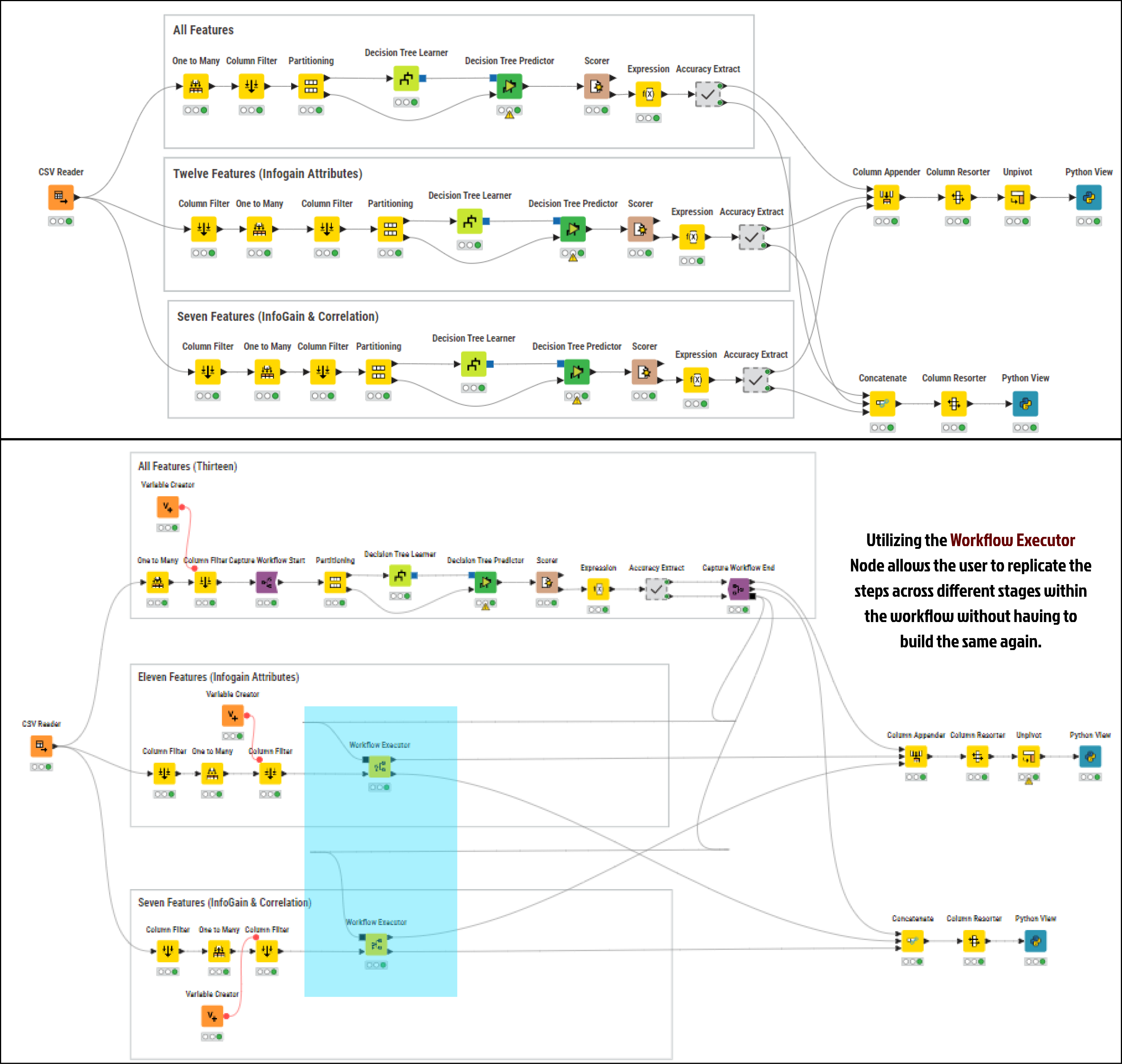
KNIME's workflow capabilities help reduce manual effort by eliminating the need to design and run multiple workflows for the three datasets. Using KNIME's workflow capture feature, we can reuse the same sequence of steps across different datasets without duplicating nodes. This also ensures that any changes to the workflow steps automatically apply across all three datasets.1
Thanks for reading. Please feel free to reach out to me on LinkedIn if you would like to discuss and share your experiences.